Building a spell checker for search in Umbraco
I spent the day building a spell checker for a search UI I've been improving. Turns out it was pretty easy when leaning on Lucene.Net Contrib. I'll show you the gist of it in this article.
Make sure you have some nice proofed data to work with tough. While writing the tests for my checker, I kept getting silly suggestions and wrong results. Turned out the data itself had quite a few typos. On the bright side, it allowed us to fix the typos.
Building a dictionary
So the first thing you need to provide spell checking is a dictionary. For my solution I went with using all the words that exists in the site so I wouldn't suggest words that don't have results. We already have something that provides this functionality, namely Examine. Examine lets you add indexes with custom indexers, and that's a perfect fit for our needs. This dictionary however only needs one field: word.
Here's the basic code for an indexer that indexes all the words in a site:
public class SpellCheckIndexer : BaseUmbracoIndexer
{
// May be extended to find words from more types
protected override IEnumerable<string> SupportedTypes
{
get
{
yield return IndexTypes.Content;
}
}
protected override void AddDocument(Dictionary<string, string> fields, IndexWriter writer, int nodeId, string type)
{
var doc = new Document();
List<string> cleanValues = new List<string>();
// This example just cleans HTML, but you could easily clean up json too
CollectCleanValues(fields, cleanValues);
var allWords = String.Join(" ", cleanValues);
// Make sure you don't stem the words. You want the full terms, but no whitespace or punctuation.
doc.Add(new Field("word", allWords, Field.Store.NO, Field.Index.ANALYZED));
writer.UpdateDocument(new Term("__id", nodeId.ToString(CultureInfo.InvariantCulture)), doc);
}
protected override IIndexCriteria GetIndexerData(IndexSet indexSet)
{
var indexCriteria = indexSet.ToIndexCriteria(DataService);
return indexCriteria;
}
private void CollectCleanValues(Dictionary<string, string> fields, List<string> cleanValues)
{
var values = fields.Values;
foreach (var value in values)
cleanValues.Add(CleanValue(value));
}
private static string CleanValue(string value)
{
return HttpUtility.HtmlDecode(value.StripHtml());
}
}
To make it actually create an index you have to add it and an IndexSet to Examine's configuration.
/config/ExamineSettings.config:
<Examine>
<ExamineIndexProviders>
<providers>
<!-- Existing providers... -->
<add name="SpellCheckIndexer" type="YourAssembly.SpellCheckIndexer, YourAssembly"
analyzer="Lucene.Net.Analysis.Standard.StandardAnalyzer, Lucene.Net"
/>
</providers>
</ExamineIndexProviders>
<!-- Search Providers - configured later -->
</Examine>
/config/ExamineIndex.config:
<ExamineLuceneIndexSets>
<IndexSet SetName="SpellCheckIndexSet" IndexPath="~/App_Data/TEMP/ExamineIndexes/{machinename}/SpellCheck/">
<IndexAttributeFields>
<add Name="nodeName"/>
</IndexAttributeFields>
<IndexUserFields>
<!-- Add the properties you want to extract words from here -->
<add Name="body"/>
<add Name="summary"/>
<add Name="description"/>
</IndexUserFields>
</IndexSet>
</ExamineLuceneIndexSets>
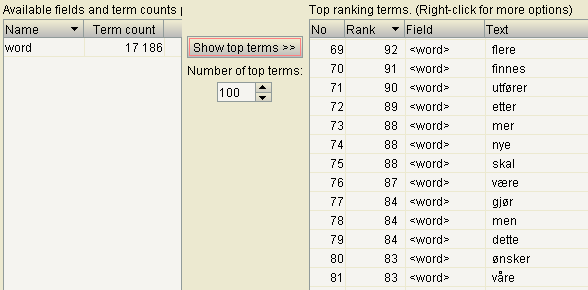
Now we're actually ready to create a word index. Open the backoffice and the developer section. Navigate to the Examine Management tab. You should see the "SpellCheckIndexer". Click it and select "Index info & tools". You might already have documents in the index. If so, we're good to go, otherwise click "Rebuild index". If you want, you can have a look at the data using Luke.
Casting the spell
Now we're ready to let the Lucene Contrib SpellChecker do its magic. It needs to get the dictionary from our index, so let's give it a searcher from Exmine. We'll configure that as a regular searcher in ExamineSettings.config:
<ExamineSearchProviders defaultProvider="ExternalSearcher">
<providers>
<add name="SpellCheckSearcher"
type="UmbracoExamine.UmbracoExamineSearcher, UmbracoExamine"
analyzer="Lucene.Net.Analysis.Standard.StandardAnalyzer, Lucene.Net"
/>
</providers>
</ExamineSearchProviders>
Now we've got everything we need to build the checker. I've written some unit-tests for it, so the constructor takes a BaseLuceneSearcher as an argument. For testing, I just create one from an index I know exists. For Umbraco I instantiate it as a singleton using the searcher from Examine.
public class UmbracoSpellChecker
{
private static readonly object lockObj = new object();
private static UmbracoSpellChecker instance;
public static UmbracoSpellChecker Instance
{
get
{
lock(lockObj)
{
if (instance == null)
{
instance = new UmbracoSpellChecker((BaseLuceneSearcher)ExamineManager.Instance.SearchProviderCollection["SpellCheckSearcher"]);
instance.EnsureIndexed();
}
}
return instance;
}
}
private readonly BaseLuceneSearcher searchProvider;
private readonly SpellChecker.Net.Search.Spell.SpellChecker checker;
private readonly IndexReader indexReader;
private bool isIndexed;
public UmbracoSpellChecker(BaseLuceneSearcher searchProvider)
{
this.searchProvider = searchProvider;
var searcher = (IndexSearcher)searchProvider.GetSearcher();
indexReader = searcher.GetIndexReader();
checker = new SpellChecker.Net.Search.Spell.SpellChecker(new RAMDirectory(), new JaroWinklerDistance());
}
private void EnsureIndexed()
{
if (!isIndexed)
{
checker.IndexDictionary(new LuceneDictionary(indexReader, "word"));
isIndexed = true;
}
}
public string Check(string value)
{
EnsureIndexed();
var existing = indexReader.DocFreq(new Term("word", value));
if (existing > 0)
return value;
var suggestions = checker.SuggestSimilar(value, 10, null, "word", true);
var jaro = new JaroWinklerDistance();
var leven = new LevenshteinDistance();
var ngram = new NGramDistance();
var metrics = suggestions.Select(s => new
{
word = s,
freq = indexReader.DocFreq(new Term("word", s)),
jaro = jaro.GetDistance(value, s),
leven = leven.GetDistance(value, s),
ngram = ngram.GetDistance(value, s)
})
.OrderByDescending(metric =>
(
(metric.freq/100f) +
metric.jaro +
metric.leven +
metric.ngram
)
/ 4f
)
.ToList();
return metrics.Select(m => m.word).FirstOrDefault();
}
}
The constructor keeps a reference to our word index and creates a SpellChecker that will do it's work in memory. When we first search for suggestions, EnsureIndex passes our word index to the SpellChecker and lets it create it's magic "back-end". It could also be on disk, but for this site the performance is good enough to do it live.
The only suggestion code you actually need in Check is basically just:
var suggestion = checker.SuggestSimilar(value, 1);
It will give you a feasible word if the value has a typo. However, in many cases it's not the one you're after. You can increase the number of suggestions you want to get a few more, but for search suggestions, we really just want one. Changing the StringDistance algorithm passed to the SpellChecker also varies the output, so you should experiment with that.
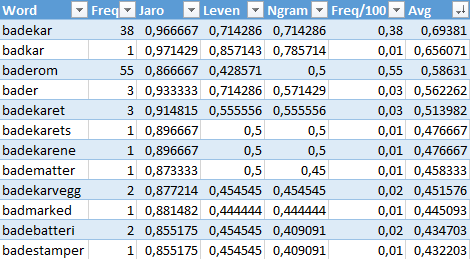
In my case there was a typo in the source data. I was testing against the Norwegian word for bathtub: "badekar". My test phrase was "badkear" and I kept getting suggestions for "badkar". That word snuck in there due to one spelling mistake in one document. So I figured word frequency should trump. But sorting the suggestions by word frequency turned out to be a bad idea. "Baderom", the Norwegian word for "bathroom", is more frequent and won over "badekar" that I was after.
I spun up all the string distance algorithms and put the results, including the document frequency of the terms in Excel. Experimenting a bit showed that the frequency divided by 100 added to the sum of the distance results was a good metric. After ordering by that result and taking the first, my checker is pretty intelligent when providing suggestions.
Getting results
Here's a snippet from the search controller that builds up the response model:
var spellChecker = UmbracoSpellChecker.Instance;
var checkedTerms = phrase.Split(' ').Select(t => spellChecker.Check(t));
var didYouMean = String.Join(" ", checkedTerms);
result.DidYouMean = didYouMean;
// Uses Lucene's TopScoreDocCollector
var totalHits = GetTotalHits(query);
if (result.DidYouMean != phrase)
{
if (totalHits == 0)
{
query = CreateQuery(result.DidYouMean);
totalHits = GetTotalHits(query);
result.Modified = true;
result.Query = result.DidYouMean;
}
else
{
result.HasAlternative = true;
}
}
When searching for "badkear" now, I get result.Modified == true. I didn't get any hits for that word, but my spell checker found the word "badekar". I can happily go search for that and tell my user I modified his search. "Did not find any hits for 'badkear', showing results for 'badekar'.
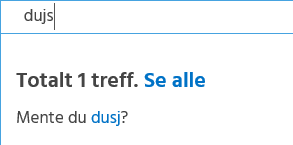
When searching for "dujs", a misspelled version of the Norwegian word for "shower", I find that we have another typo in our data. I get result.Modified == false, but result.HasAlternative == true. My spell checker dutifully asks if I ment "dusj". "Showing 1 result. Did you mean 'dusj'?"
There's a lot more you can do with this to provide even more accurate suggestions. For my purposes however, this was all I needed. Leaning on Lucene Contrib when you need some fancy search functionality will almost always save the day.
If you want to know more about Lucene, I recommend getting the book called "Lucene in Action".